PrismaとNeonを初めて使うので、ドキュメントを見ながらセットアップする
やる理由
厳密には、Prismaは自分の結婚式で作った余興のクイズアプリケーションで使用したのだけれど、そのときはChatGPTとか使ってだいぶ適当にやってしまったため、マイグレーションするたびになぜかエラーが出てトホホ、、となった経験がある(結果、毎回泣く泣くprisma関連のディレクトリを消して無理やりinitialなマイグレーションにしていた)。
個人開発とかだと、簡単なCRUD要件のAPIを作るためだけに、Railsを使うのは少しリッチすぎるかもしれないと思ったので、改めてPrismaに入門してみたい。
やってみる
このドキュメントに沿ってPrismaをクイックスタートしてみる。
Neonのセッティング
と、Prismaに入る前に、まず先にDBのセットアップをしておく。
以前個人開発でPlanetScaleを使っていたが、無料プランがなくなったので、代わりにNeonにした。 NeonもPlanetScale同様、ブランチ機能で本番/ステージングなど各環境の管理を担保している。
会員登録したあと、PostgreSQLのバージョンとリージョンをぽちぽちと指定した上でプロジェクトを作成する。 リージョンに東京はなかったので、シンガポールを設定した。
これでDBのセットアップ完了、非常に楽。
スキーマの作成
ここからは上に載せた、Prismaのドキュメントに従い進める。
npx prisma initでスキーマファイルの作成をしてくれる。
クイックスタートのドキュメントではsqliteを使った例になっているが、今回はPostgreSQLを使いたいのでそう指定する。
初回のマイグレーション実行
次に、お試しとして2つテーブルをDBに追加したい。 スキーマに以下のようにmodelを追加する。
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
}
スキーマのmodelには2つ役割がある。
前者はRailsのschema.rbと同じ役割だが、加えて後者により、PrismaクライアントをNode.jsで使うときにエディタがテーブルの型情報を教えてくれるようになる。
スキーマを修正したので、次はPrismaがDBに対してマイグレーションをかけれるようにする。
init時に、schema.prismaがこういう風になっている。
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
ので、.envに冒頭のNeonのセットアップによって発行されたURLを設定すればよい。
末尾にsslmode=requireを付けるとセキュアな通信になると勧められていたので付ける。
また、hostnameの一部であるendpointIDの末尾に-poolerを付けると、Neonのプールされたコネクションを使用するらしいので付ける。
プールされていることで、コネクションの確立や切断の度に発生する負荷を減らすことができる。
準備OKとなったので、npx prisma migrate dev --name initで最初のマイグレーションを走らせる。
このコマンドは3つの仕事を持っている。
雑にいうとRailsのrails db:migrateにあたる。
実行後、無事Neonの画面でUserテーブルとPostテーブルが作成されたことを確認。
実際にDBと会話できるか確認
Node.jsからDBに対して、データの作成および取得ができるか確認する。
データを投入するためのスクリプトをts-nodeを使って実行せよとドキュメントにはあったが、手元でやるとESModule関連のエラーが出た。
解決に時間をかけることでもないと思ったので、あらかじめinitしていたNext.jsのページコンポーネントにボタンを置き、それをぽちぽちしてRoute Handlers経由でPrismaを実行することにした。
export async function POST(request: NextRequest) { const res = await prisma.user.create({ data: { name: "Bob", email: "bob@prisma.io", }, }) console.log("res", res) const users = await prisma.user.findMany() console.log("users", users) return NextResponse.json({ ok: true }) }
上記のログとNeonのGUI確認によって、データの作成も取得もできていることを確認した。
2回目以降のマイグレーション
テーブルにデータが入った状態で、そのテーブルに対して追加の変更を加えたい。
たぶんこれに従えばよさそう。
今回はスキーマファイルのUser modelにageカラムを追加する。
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
age Int
posts Post[]
}
npx prisma migrate dev --name add_ageとして、マイグレーションを実行する。
しかしこういうエラーで阻まれる。
Step 0 Added the required column `age` to the `User` table without a default value. There are 3 rows in this table, it is not possible to execute this step. You can use prisma migrate dev --create-only to create the migration file, and manually modify it to address the underlying issue(s). Then run yarn prisma migrate dev to apply it and verify it works.
ageをNOT NULLとしたので、デフォルト値が設定されていないままのマイグレーションはできない。たしかにそうか。
言われた通り、--create-onlyを付けて、再度マイグレーションコマンドを叩く。するとマイグレーション内容のSQLファイルだけが先に発行された。
直接編集して、以下のようにDEFAULT値を設定する。
ALTER TABLE "User" ADD COLUMN "age" INTEGER DEFAULT 10 NOT NULL;
ここで再度npx prisma migrate devを実行すると、無事カラム追加のマイグレーションが通った。
ここでセットアップを終わりとする。
感想
PrismaのドキュメントにはNeonのページもあり、そこにはサーバーレスやエッジ環境でPrisma + Neonを使うときの追加設定も載っていたが、今回その環境を使う予定はないのでひとまず触れないでおく。
Next.jsのチュートリアルを終了したので雑で断片的なまとめ
概要
Next.jsのチュートリアルを終了した。
雑なまとめを書きたいと思ったが、ZennやQiitaなどのプラットフォームに書くことではないと思ったので、こっちに書く。
雑で断片的なまとめ
Fast Refresh
たしかに開発環境での変更箇所のブラウザへの反映(Refresh)は少し速かった。ただ「これってそこまで速いのかな?」とはなった。業務ではGatsby.jsを使っており、Gatsby.jsもFast Refreshを同様に謳っているので、いずれにせよ速いということで、そこまでの恩恵を感じれなかったのかもしれない。
Linkの中にはaタグを入れる
Linkコンポーネントは、中に文字列を入れるだけでもページ遷移自体はできる。理由は、自動でaタグを挿入してくれるため。しかしその形はDeprecated(非推奨)なので、やはりLinkの中にはaタグを入れるのがよさそう。
クライアント側でのページ遷移
Linkが提供してくれるのはサーバーを挟んでのページ遷移ではなく、JavaScriptによるクライアント側での遷移。サーバーを経由していないので、合計の処理時間が短い。ページ遷移の速さは結構感じた。
code splitting
Next.jsは自動的にコードを分割するから、どのページも必要な時だけローディングを行う。つまりトップページがレンダリングされた際も、他のページのコードが最初から供給されている、というわけではない。
なので、サービスが数百のページを抱えていたとしても、トップページのローディングは素早く行えることが保証される。
またページがそれぞれ独立しているので、もしあるページでエラーが発生したとしても、アプリの残りの部分は動き続ける。優秀。
hydration
ページがブラウザによってローディングされる際に、中にあるJavaScriptコードが走ってページ全体をインタラクティブにする。この過程をhydrationと呼ぶ。
next-env.d.tsはいじってはダメ
next-env.d.tsはいじらない方がいいファイルらしい(いじろうとしてた)。
感想
チュートリアル、原文も結構分かりやすかったけど、英語読むのが大分めんどうだったのでこちらの記事と2窓で読み進めてた。
Draft.js製テキストエディタの内容をFireStoreに保存する
はじめに
Draft.js製テキストエディタに入力されたデータをFireStoreに保存する手順を記録します。
正確には、今回エディタのコンポーネントを取ってきているライブラリはDraft.jsではなく、react-draft-wysiwygというDraft.jsをさらに拡張させたライブラリになります。
ですが今回やりたいことであるデータの書き込みをする限りではエディタのコンポーネントに限っては2つのライブラリ間で何か特別な機能の差異があるわけではないので、実装する際は好きな方を使用してもらって問題ありません(Draft.jsのエディタでも今回やりたいことができるのは確認済み)。
ちなみに私がreact-draft-wysiwygを使っているのは、ツールバーをめちゃくちゃ簡単にエディタにくっつけられるからです。
また、「Draft.js製エディタの内容をDBに書き込む」ことについては、Wantedlyのエンジニアの方が執筆されている以下の記事をとても参考にさせていただきました。
なのでほとんど上記の記事を読めばOKなのですが、上記の記事では、簡単のためlocalStorageへの保存までで説明を終えているため、本記事では実際にDB(今回はCloud FireStore)への書き込み処理を行うまでを取り扱おうと思います。
前提
- Draft.jsもしくはreact-draft-wysiwygで入力可能なエディタを作成済
- (手前味噌ですが、未実装の方はこちらの記事からどうぞ)
- 環境変数などを用いてfirebaseのinitializeAppが完了済
- firestore.rules作成済
環境
- react 17.0.1
- typescript 4.5.4
- gatsby 4.3.0
- @emotion/react 11.7.0
- @mui/material 5.2.7
- draft.js 0.11.7
- react-draft-wysiwyg 1.14.7
コード全文
import React, { useState } from "react" import firebase from "../firebase" import { css } from "@emotion/react" import { Button } from "@mui/material" import { Editor } from "react-draft-wysiwyg" import { EditorState, convertToRaw, convertFromRaw, ContentState, } from "draft-js" import "react-draft-wysiwyg/dist/react-draft-wysiwyg.css" const db = firebase.firestore() const save = async (data: string) => { await db.collection("articles").doc().set({ content: data }) } const Article = () => { const initData = convertFromRaw({ entityMap: {}, blocks: [ { key: "key", text: "", type: "unstyled", depth: 7, entityRanges: [], inlineStyleRanges: [], data: {}, }, ], }) const initState = EditorState.createWithContent(initData) const [editorState, setEditorState] = useState(initState) const handleChange = (state: EditorState) => { setEditorState(state) } const onSave = async (contentState: ContentState) => { const object = convertToRaw(contentState) const data = JSON.stringify(object) console.log(data) await save(data) } const handleSubmit = async (event: React.FormEvent<HTMLFormElement>) => { event.preventDefault() await onSave(editorState.getCurrentContent()) } return ( <form onSubmit={handleSubmit}> <div onClick={focus} css={css` box-sizing: border-box; border: 1px solid #ddd; cursor: text; padding: 16px; border-radius: 2px; margin-bottom: 2em; box-shadow: inset 0px 1px 8px -3px #ababab; background: #fefefe; height: 200px; `} > <Editor editorState={editorState} onEditorStateChange={handleChange} placeholder="書きたいことを入力してください" toolbar={{ options: ["inline", "blockType", "list", "textAlign", "link"], inline: { options: ["bold", "strikethrough"], }, blockType: { inDropdown: false, options: ["H2"], }, list: { options: ["unordered"], }, textAlign: { options: ["center"], }, link: { options: ["link"], }, }} /> </div> <Button type="submit" variant="contained"> 保存 </Button> </form> ) } export default Article
手順
1. FireStoreにデータを保存するための関数作成
FirebaseをinitializeAppしているファイルからfirebaseというnamespaceをimportします。 そしてそれをもとにデータ保存用の関数を書いていきます。
具体的には、そのnamespaceをもとにFireStoreの今回書き込みをするドキュメントのパスを指定し、そこにdataを投入するという形です。
ちなみにcollectionが持つdocメソッドは引数を入れずに使用すると、勝手にドキュメントのidを作成してくれるので便利です。
import firebase from "../firebase" const db = firebase.firestore() const save = async (data: string) => { await db.collection("articles").doc().set({ data }) }
またnamespaceであるfirebaseをexportしているファイルはこんな感じです。
import "firebase/compat/firestore"がないとFireStoreへはアクセスできないので注意です。
import firebase from "firebase/compat/app" import "firebase/compat/auth" import "firebase/compat/firestore" const firebaseConfig = { apiKey: process.env.REACT_APP_FIREBASE_API_KEY, authDomain: process.env.REACT_APP_FIREBASE_AUTH_DOMAIN, projectId: process.env.REACT_APP_FIREBASE_PROJECT_ID, storageBucket: process.env.REACT_APP_FIREBASE_STORAGE_BUCKET, messagingSenderId: process.env.REACT_APP_FIREBASE_MESSAGE_SENDER_ID, appId: process.env.REACT_APP_FIREBASE_APP_ID, measurementId: process.env.REACT_APP_FIREBASE_MEASUREMENT_ID, } firebase.initializeApp(firebaseConfig) export const auth = firebase.auth() export default firebase
2. テキストエディタに入力されたデータをJSONに変換する関数作成
関数にはContentStateというクラスを型にした引数を入れます。
ContentStateとは、Draft.jsのエディタの状態を管理しているEditorStateというクラスの中で、入力された文章の内容を保持する役割を持つクラスです。これはDraft.jsが提供してくれています。
convertToRawはContentStateが持つデータ構造をよりシンプルなものに変換するための関数です。こちらもDraft.jsで提供してくれているのでimportしましょう。
データ構造をよりシンプルにしたあとは、そのオブジェクトをstringに変換します。 そして最後に1で作成した関数の引数としてそのデータを入れてあげます。
import { convertToRaw, ContentState, } from "draft-js" const onSave = async (contentState: ContentState) => { const object = convertToRaw(contentState) const data = JSON.stringify(object) console.log(data) await save(data) }
脇道にはそれますが、引数の型に当てているContentStateはクラスとしてimportしてきています。 それなのに型として使うことができ、かつ型を当てた引数がクラスのメソッドとか使えちゃうのはどういうことなのでしょうか?
ここについては、厳密には違うかもしれませんが以下の記事にそれらしいことが書いてありました。
TypeScriptでは、クラスを定義すると同時に同名の型も定義されます。 この例では、クラスFooを定義したことで、Fooという型も同時に定義されました。Fooというのは、クラスFooのインスタンスの型です。
つまりTypeScriptでは、クラスを定義すると同名の型を勝手に定義してくれて、その型はクラスのインスタンスの型になるので、上記に挙げたことが可能になっているようです。
そこまで自信はないので、何か認識が誤っていることに気づいた方はご指摘いただけると幸いです🙏
3. 2の関数のトリガーとなるボタン作成、およびデータ送信のための関数とform作成
ボタンはMaterial UIで作成します。 ボタンが押されたらformが連動するようformの中にonSubmitを設け、そこにはhandleSubmitを入れます。
handleSubmitではpreventDefaultをしてページのリロードを防いだのち、2の関数を呼び出しています。 そしてその引数には、useStateのフックで管理しているeditorStateという状態の、さらにgetCurrentContentというメソッドを使用したデータを入れています。getCurrentContentはエディタに実際に入力されている文章データが取得するためのメソッドです。
import { Button } from "@mui/material" const Article = () => { const initData = convertFromRaw({ entityMap: {}, blocks: [ { key: "key", text: "", type: "unstyled", depth: 7, entityRanges: [], inlineStyleRanges: [], data: {}, }, ], }) const initState = EditorState.createWithContent(initData) const [editorState, setEditorState] = useState(initState) const handleSubmit = async (event: React.FormEvent<HTMLFormElement>) => { event.preventDefault() await onSave(editorState.getCurrentContent()) } return ( <form onSubmit={handleSubmit}> <div onClick={focus} css={css` box-sizing: border-box; border: 1px solid #ddd; cursor: text; padding: 16px; border-radius: 2px; margin-bottom: 2em; box-shadow: inset 0px 1px 8px -3px #ababab; background: #fefefe; height: 200px; `} > <Editor editorState={editorState} onEditorStateChange={handleChange} placeholder="書きたいことを入力してください" toolbar={{ options: ["inline", "blockType", "list", "textAlign", "link"], inline: { options: ["bold", "strikethrough"], }, blockType: { inDropdown: false, options: ["H2"], }, list: { options: ["unordered"], }, textAlign: { options: ["center"], }, link: { options: ["link"], }, }} /> </div> <Button type="submit" variant="contained"> 保存 </Button> </form> ) }
4. firestore.rulesの変更
以下結構ゆるめに書いています。rulesはもっとこう書かないといけない、というご指摘がある方はご助言いただけますと幸いです。
isValidArticleで、dataがちゃんとFireStoreに投げた通信の中に入っているか、かつその型がstringかどうかを調べます。 isAuthUserというログインしているかをチェックする関数も設けてはいますが、内容的にはこの記事にはあまり関係しないのでミニマムで実装される場合はなくても大丈夫です(このエディタを何かのサービスに組み込むときには必要です)。
FireStoreはホワイトルール形式なので、〜という場合はcreateを許可する、という風に書きます。 以下ではisValidArticleとisAuthUserがそれぞれtrueであれば許可すると書いています。
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
function isAuthenticated() {
return request.auth != null;
}
function isUserAuthenticated(userId) {
return userId == request.auth.uid;
}
function isAuthUser(userId) {
return isAuthenticated() && isUserAuthenticated(userId);
}
function isValidArticle(article) {
return article.size() == 1
&& 'data' in article && article.data is string;
}
match /articles/{docId} {
allow create: if isAuthUser(request.auth.uid) && isValidArticle(request.resource.data);
}
}
}
5. done 🙌
こちらが出来上がった画面です。
 実際にエディタにデータを入力して、保存ボタンを押してみましょう!
firestoreを見にいくと、実際に入力した文章データがJSONで保存されているのがわかります(スクショの右あたりに"text":"ほげほげ"が入っている)。
実際にエディタにデータを入力して、保存ボタンを押してみましょう!
firestoreを見にいくと、実際に入力した文章データがJSONで保存されているのがわかります(スクショの右あたりに"text":"ほげほげ"が入っている)。
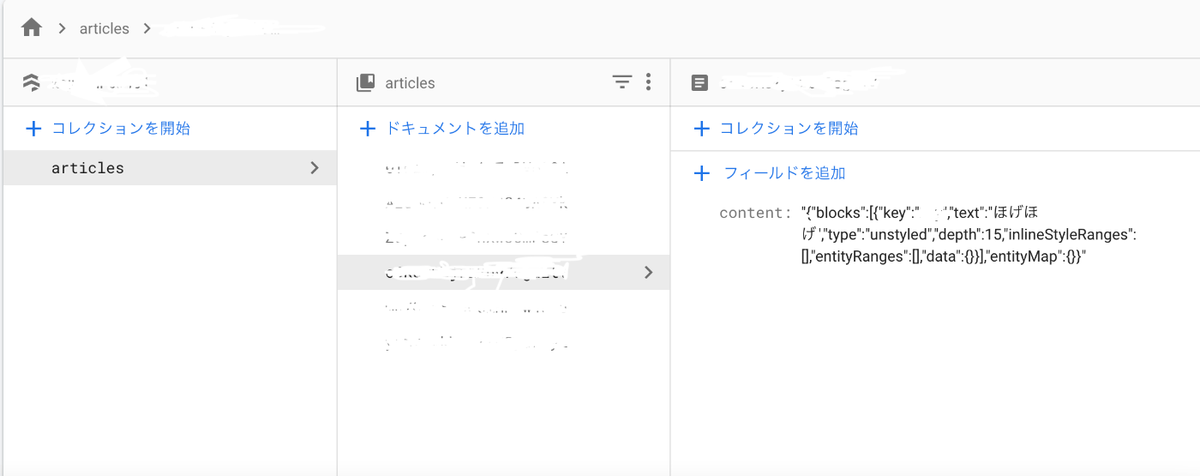
このtextというデータだけをFireStoreに保存しないのは、JSONのままの方が、エディタの内容を復元しやすいと思っているためです(まだ試していないですが)。 おそらくは、DBからJSONをgetしたのち、2で行っているconvertToRaw()とJSON.stringify()の逆の処理を行なってやれば復元できると思われます。
所感
Draft.jsエディタのDBへの書き込み処理は、基本的なところかもしれないですが、個人的にはつまづいたポイントでした。 Draft.jsの情報ソースは割と少ないので、困っている方の一助になれば幸いです。
React Draft Wysiwygを使ってシンプルなテキストエディタを作成する
概要
今作っているアプリの中にテキストエディタを投入したいとなったので、取り急ぎ作成しました。
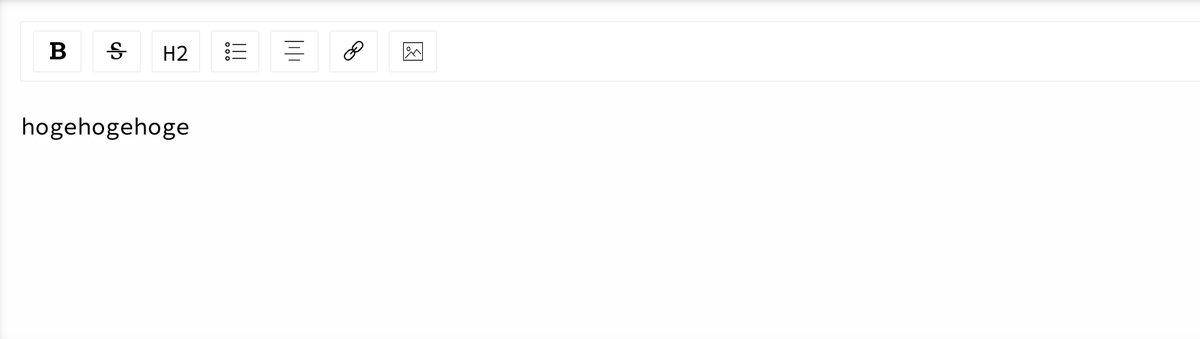
完成形
環境
選定したライブラリ
react-draft-wysiwygを選びました。
これはDraft.jsという、Facebook社が開発しているテキストエディタ用ライブラリをさらに拡張させたライブラリです。
今回は「シンプル」かつ「欲しい機能が既に載っている」という点でこちらのライブラリを選びました。
素のDraft.jsや、その機能を拡張したDraft.js Plugins、その他Draft.jsを土台としたサードパーティなど、エディタを作っていく上で選択肢はいくつかあり、実際はじめはこれら別の選択肢に手を出したりしたのですが、結局以下の理由で採用しませんでした。
- 欲しい機能を実装するにあたり、Draft.jsの情報源が少ないため、ニッチなところでつまづいた際の対応がむずかしい&時間がかかる
- デフォルトのUIがごちゃごちゃしている
- TypeScriptに対応していない
- 長い間メンテナンスされていない
1個目の理由に関しては、例えば、範囲選択したときだけ表示されるツールバーを実装しようとした際、かな→漢字変換したときの範囲選択をケースから除外しようとして結局無理だったりしました🥲
したこと
1. react-draft-wysiwygのインストール
yarn add react-draft-wysiwyg
2. importと利用
こちらがエディタ用コンポーネントのコード全文です。説明の必要そうな箇所の意味を簡単に追っていきます!
import React from "react"
import { Link } from "gatsby"
import { Editor } from "react-draft-wysiwyg"
import "react-draft-wysiwyg/dist/react-draft-wysiwyg.css"
import { css } from "@emotion/react"
const Article = () => {
return (
<div
onClick={focus}
css={css`
box-sizing: border-box;
border: 1px solid #ddd;
cursor: text;
padding: 16px;
border-radius: 2px;
margin-bottom: 2em;
box-shadow: inset 0px 1px 8px -3px #ababab;
background: #fefefe;
`}
>
<Editor
toolbar={{
options: ["inline", "blockType", "list", "textAlign", "link"],
inline: {
options: ["bold", "strikethrough"],
},
blockType: {
inDropdown: false,
options: ["H2"],
},
list: {
options: ["unordered"],
},
textAlign: {
options: ["center"],
},
link: {
options: ["link"],
},
}}
/>
</div>
)
}
export default Article
import React from "react"
import { Editor } from "react-draft-wysiwyg"
import "react-draft-wysiwyg/dist/react-draft-wysiwyg.css"
import { css } from "@emotion/react"
適宜import。
import "react-draft-wysiwyg/dist/react-draft-wysiwyg.css"はエディタのデフォルトのstyleを保つために必要。
<div
onClick={focus}
css={css`
box-sizing: border-box;
border: 1px solid #ddd;
cursor: text;
padding: 16px;
border-radius: 2px;
margin-bottom: 2em;
box-shadow: inset 0px 1px 8px -3px #ababab;
background: #fefefe;
`}
>
</div>
エディタへのCSS適用。枠線を濃くしたり、枠内に影つけたり。
<Editor
toolbar={{
options: ["inline", "blockType", "list", "textAlign", "link"],
inline: {
options: ["bold", "strikethrough"],
},
blockType: {
inDropdown: false,
options: ["H2"],
},
list: {
options: ["unordered"],
},
textAlign: {
options: ["center"],
},
link: {
options: ["link"],
},
}}
/>
エディタの表示。デフォルトのままだとツールバーのツールがてんこもり(20個くらいある?)なので、optionsなどのpropsでその辺を絞っています。
上記のコードだと太字(bold)、取り消し線(strikethrough)、見出し(H2)、箇条書き(unordered)、中央寄せ(center)、リンク(link)の機能を残しています。
3. 完成!
完成形の画像は記事の一番上にあります🙌
所感
実装超かんたん!
だけどDraft.jsというライブラリのさらにそのまたライブラリを使っているので、今後のメンテナンスが活発でない場合はReactや関連モジュールのアップデートのタイミングで妙なエラーとか出そうで怖い・・・
JavaScript非同期処理サイクルの紙芝居
概要
JavaScriptではシングルスレッドで処理が行われる。
スレッドとはコンピューターが実行する処理の一本の流れのことであり、「シングルスレッドで処理が行われる」ということは、「複数のスレッドで並列して処理を進めることはできない」ということである。
つまり厳密に言うとJSでは並列処理は行えない。
では、一見並列処理をしているように見える非同期処理を実行している際、JSエンジンおよびブラウザ内部はどのような挙動をしているのか?
これを理解するためには、Call Stack, WebAPI, Queue, Event Loopという4つの装置をおそらく知る必要があるため、それぞれざっくり概要を書く。
JSの処理サイクルを回す装置
Call Stack
- プログラムの中で現在どのタスク(関数)が実行されているかを記録しているところ。つまりここに記録されている関数が現在メインスレッドで実行されているもの
- LIFO(後入れ先出し)
- 後からStackに追加されたタスクが常に先にスレッドで実行される
- JSエンジンの機能
WebAPI
- DOM eventやsetTimeoutなどの非同期的な関数を実行するところ
- ブラウザ内の機能
Queue
Event Loop
- Call Stackが空の場合にQueueにあるタスクをCall Stackに渡すところ
- 「Call Stackに現在実行中のタスクがないこと」と「Queueにタスクがあるか」をループ的に確認している
- ブラウザ内の機能
- Call Stackが空の場合にQueueにあるタスクをCall Stackに渡すところ
非同期処理のサイクル
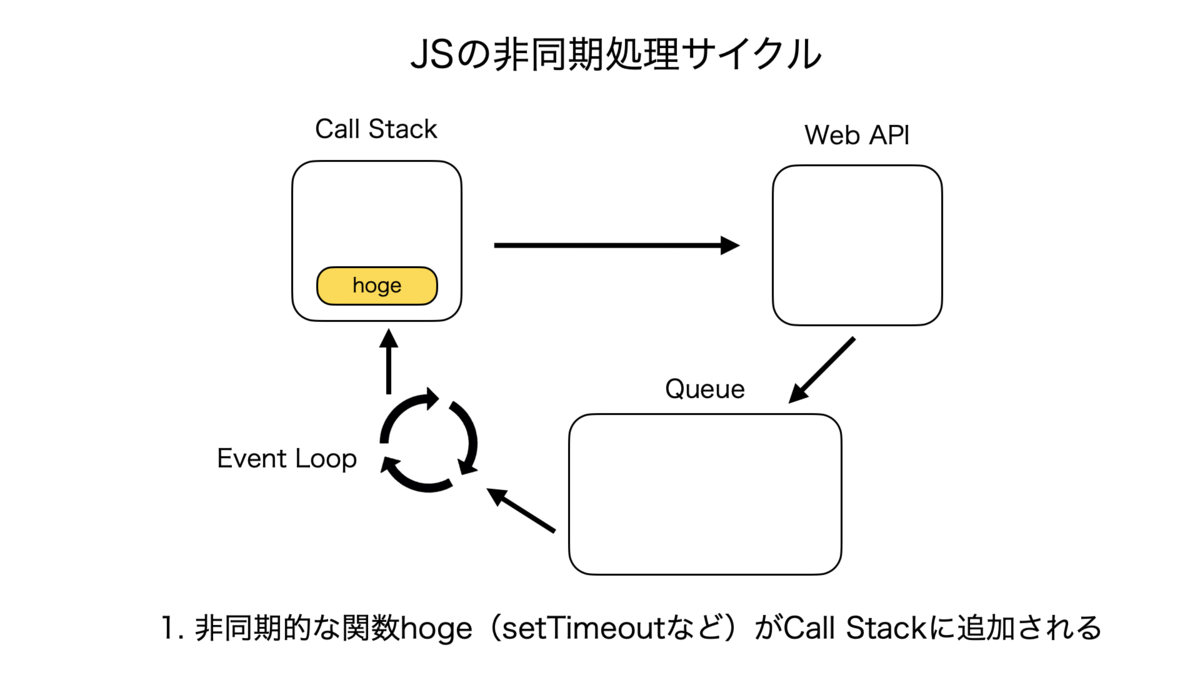
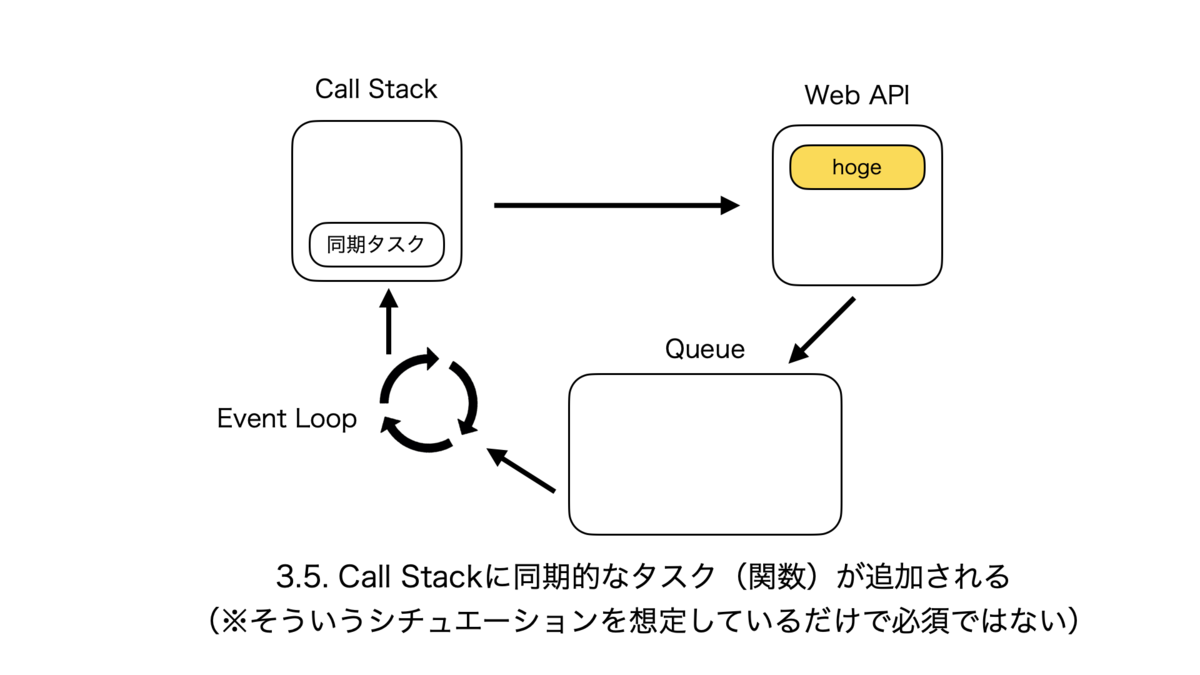
同期処理のサイクルはとても単純で、Call Stackに関数hogeが追加されて、処理が終了し次第次の関数がまた追加される、というものである。
非同期処理のサイクルは複雑なので紙芝居で表現する。こんな感じ。


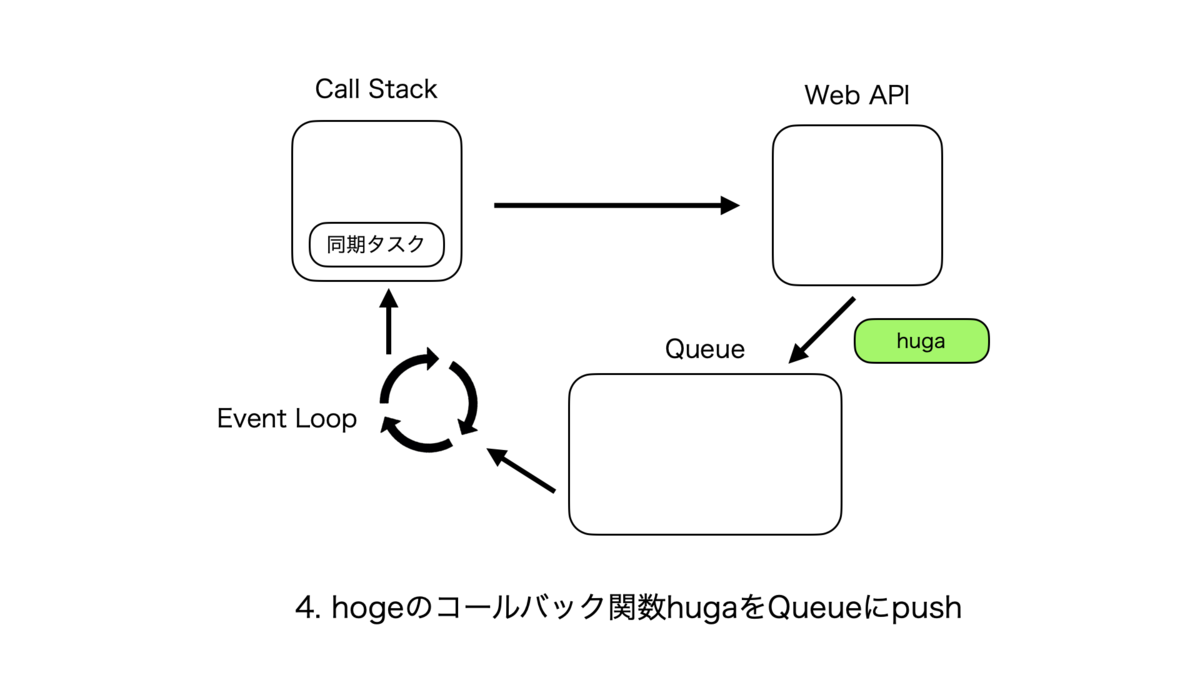
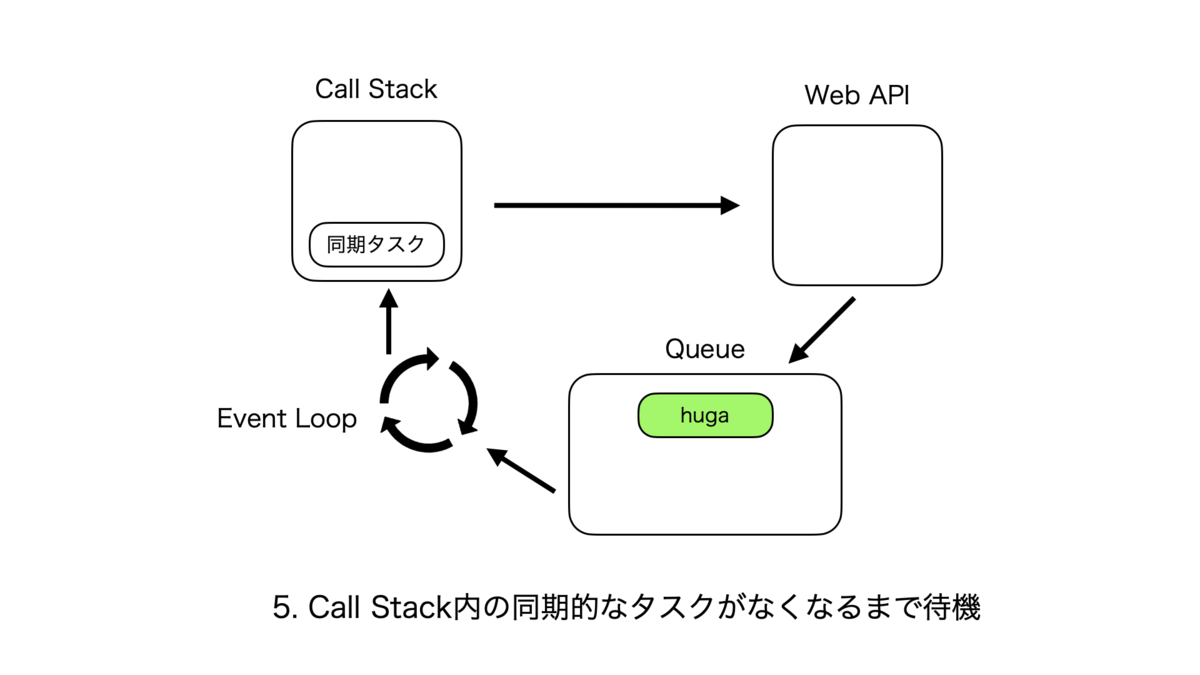
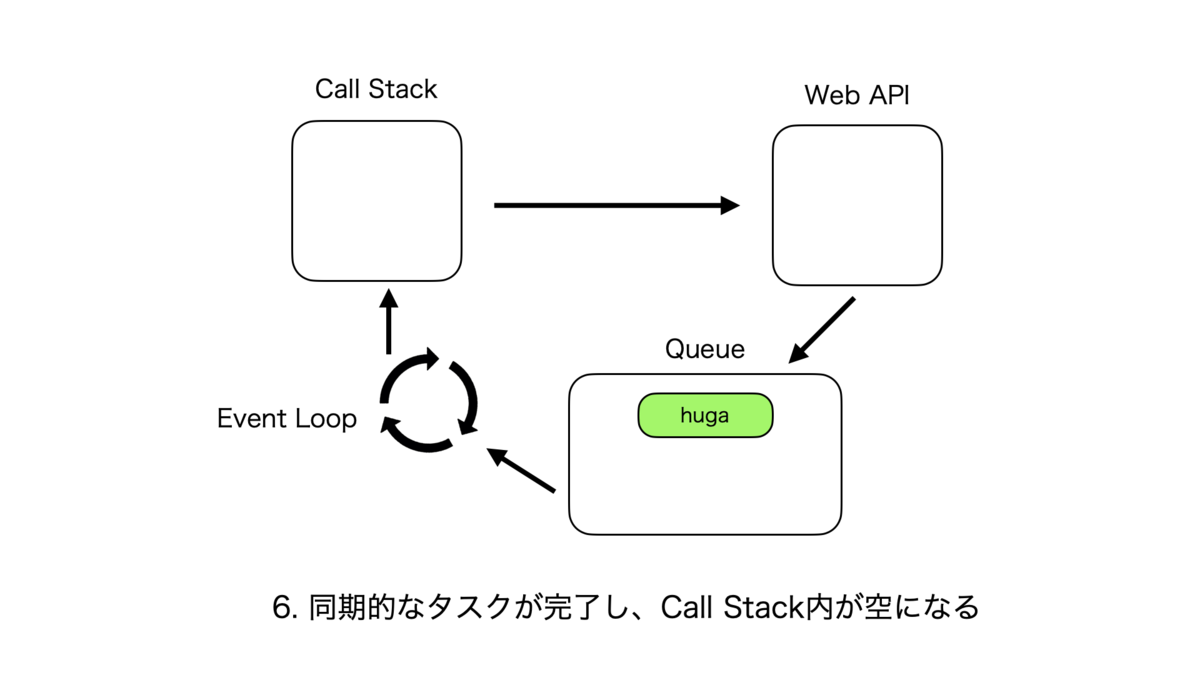
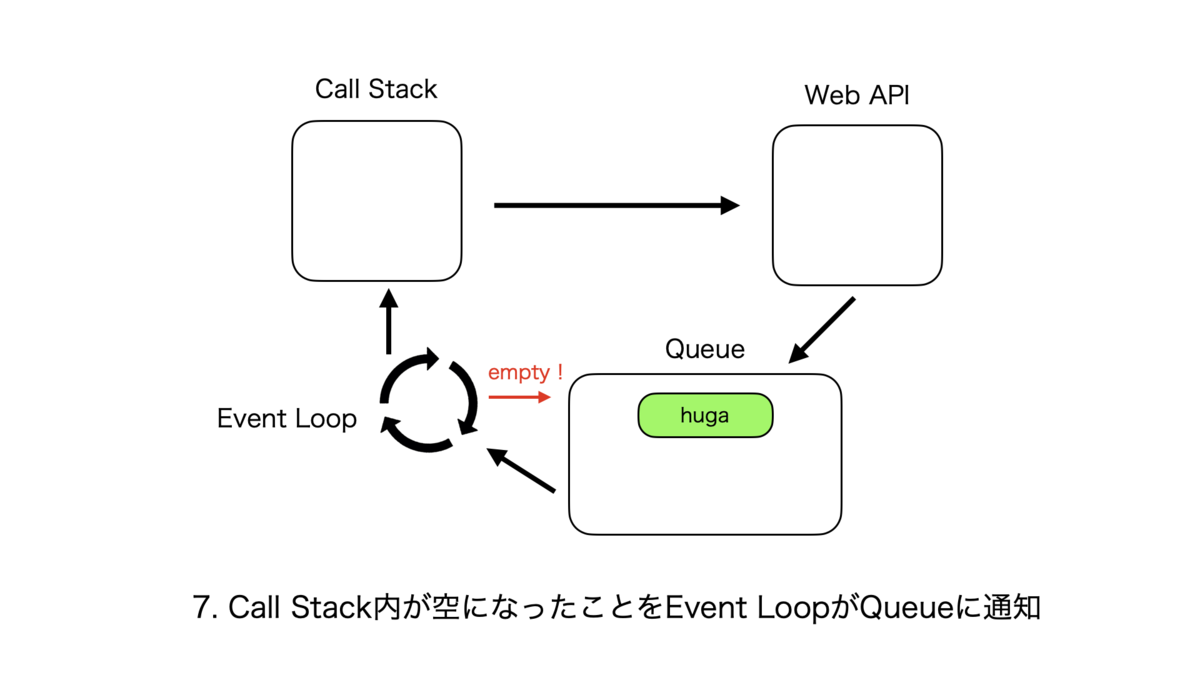
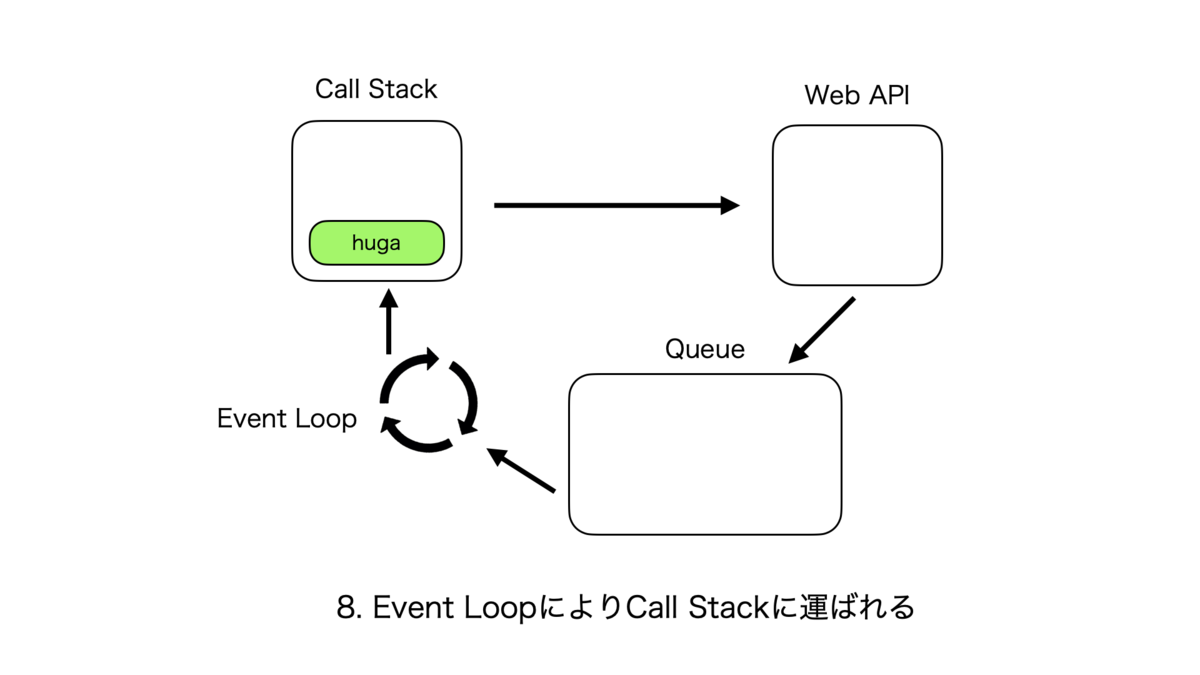
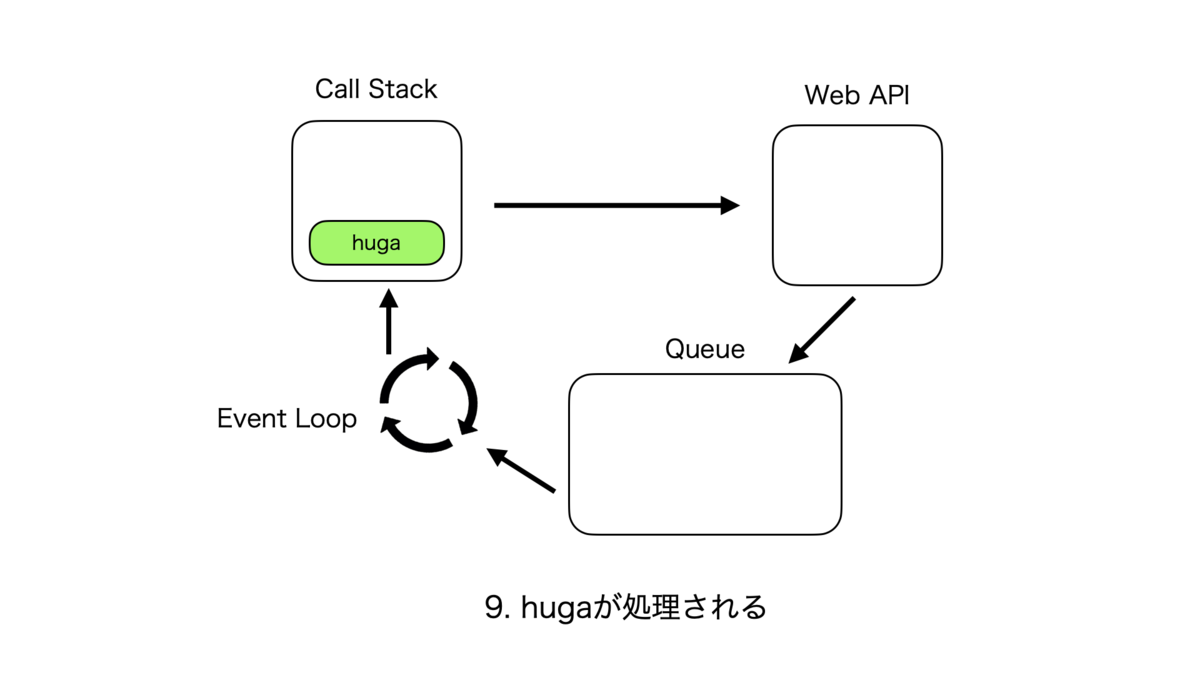
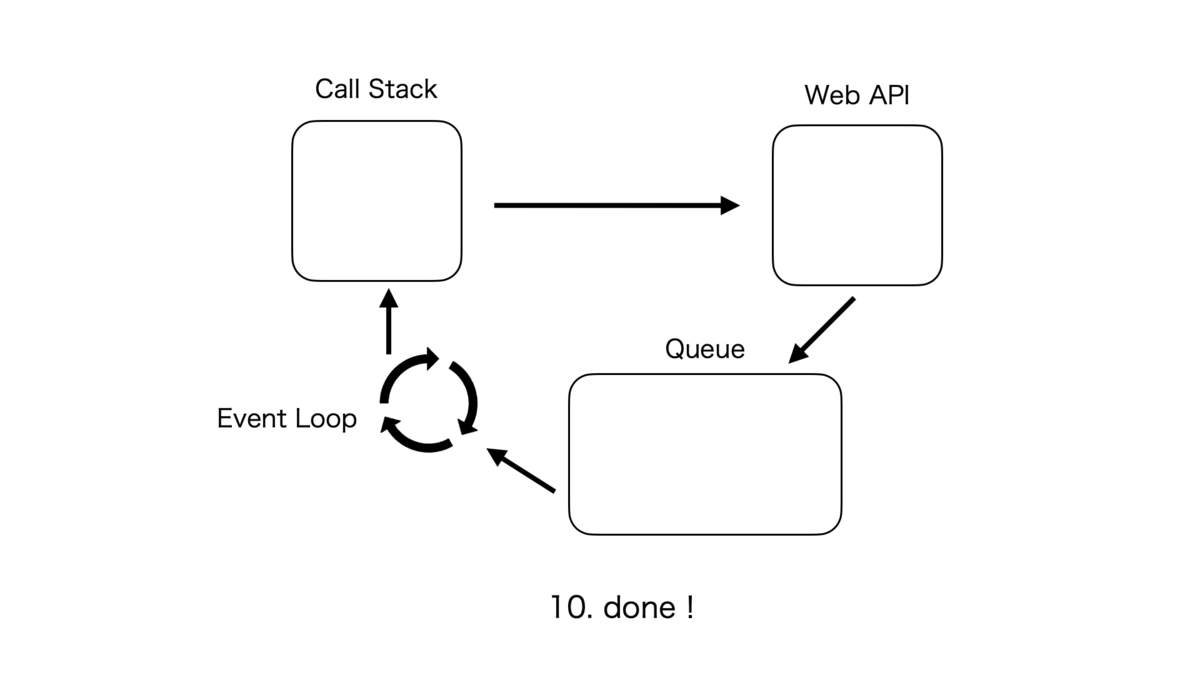
Call StackとそれぞれのQueueの優先度
処理が実行される優先度は、Call Stack > Micro Task Queue > Macro Task Queue となる。
フローとしては、シングルスレッドであるCall Stackでタスクがなくなると次はMicro Task上のタスクがCall Stackに渡され、それが全てなくなるとMacro Task上のタスクが同様に渡される。
所感
諸々調べてたら、この辺のサイクルをさらに視覚的に分かりやすく理解できそうないい感じのLoupeっていうサイトを見つけた。また使いたい!
参考記事
【図解】1から学ぶ JavaScript の 非同期処理 - Qiita
JavaScriptはなぜシングルスレッドでも非同期処理ができるのか/Why Can JavaSctipt Invoke Asynchronous in Single Thread?
15分で理解するJavaScriptのイベントループ - Qiita
Call stack (コールスタック) - MDN Web Docs 用語集: ウェブ関連用語の定義 | MDN
最近TSとJSについて学んだことを乱雑にまとめる
TS
インデックス型のオブジェクト
名称が定義されていないプロパティを持ったオブジェクトを作成することができる。
例えばkeyを文字列、valueが数値のプロパティを作成したい場合は [K: string]: number と記述する。 その場合は以下のようにプロパティを後から追加することができる。
let obj: {
[K: number] : string;
};
obj = { a: 1, b: 2 };
obj.c = 3;
obj["d"] = 4;
JS
プロトタイプの作成方法
オブジェクトAを作成した後に const オブジェクトB = Object.create(オブジェクトA) とすると、Aを原型(プロトタイプ)とした新しいオブジェクトBを作成することができる。
例えば以下では、元とnameが異なるオブジェクトを作成している。
const button: { name: string } = { name: 'ボタン' };
const dangerousButton = Object.create(button);
dangerousButton.name = 'ぜっっったいに押すなよ!!!';
Rubyのような、クラスを元にして新しいオブジェクトを作成するクラスベース言語と比較して、こうした元々作成しているオブジェクトから、同じ構造・データ内容のさらに別のオブジェクトを作成する言語全般のことをプロトタイプベース言語と呼ぶ。
プロトタイプベースを私たちの普段の仕事で例えると、「前回使用した書類をひな形として今回必要な書類を作成すること」はかなり考え方として似通っているとのこと。
また継承はclassとextendsを用いての記法でも可能だが、このObject.createの記法でも実施可能である。
this
JavaScriptにおけるthisが何を指し示しているかは4パターンに分けられる。 以下の記事にてその4パターンについてまとめられていた。それをほんの少し改変したものを以下に書く。
Javascriptでオブジェクト指向するときに覚えておくべきこと - Qiita
(さらにその記事は以下の2記事の内容をまとめていた)
| メソッド呼び出しパターン | 何かに所属している時のthis | |
| 関数呼び出しパターン | トップレベル(グローバルオブジェクト)のthis | |
| コンストラクタ呼び出しパターン | コンストラクタ内のthis | |
| apply,call呼び出しパターン | function#apply とか function#call とかで無理矢理変更した時のthis |
関数内でthisを使用するとトップレベルを参照するが、strictモードがONになっているとトップレベルの情報ではなくundefinedが格納されてしまう。
この事象を防ぐためには呼び出す関数の記法としてアロー関数を使用すればよい。 アロー関数内でthisを使用すると、トップレベルではなく関数の外にあるオブジェクトのthis値を参照するため、結果的に意図していた通りにthisが機能してくれることとなる。
例えば以下のコードでは、doIt内のthisはその外にあるメソッドの、greetのthisを参照している。
そしてgreetのthisはと言うとその外にあるクラスの、Personを参照している。
そのためPersonのインスタンスであるcreamyにおいてgreetを実行すると、doIt => greet => creamyという流れでthisはcreamyを参照をして、結果ととしてcreamy.greet()を実行すると「Hi, I'm Mami」が出力される。
class Person {
constructor(name) {
this.name = name;
}
greet() {
const doIt = () => {
console.log(`Hi, I'm ${this.name}`);
doIt();
}
}
}
const creamy = new Person('Mami');
creamy.greet();
Webpackとモジュールシステム
webpackがコードをバンドルする過程で、ES Modules(import・exportをJS内で利用するためのモジュールシステム)がコード全体に適用されるためにimport等が結果的に使用できるようになる。
加えてCreate React AppによってReactアプリを作成するとWebpackは勝手にインストールがされているので、開発者はimport等が使用可能な環境かどうかを気にせずに済む。
webpackなどのバンドラの存在意義として「ES Modulesをコードに適用させる」というのは1つ大きな点として挙げられるが、一方で普通に「js等の各ファイルの依存関係を解決して、1つにまとめる」という意義も依然として大きいため、ES Modulesがブラウザ・node等のJSの実行環境に元々から組み込まれるようになったとしても、バンドラはおそらく利用され続けるだろう、とのこと。
まとめていないまとめ
今の職場ではReactとTS使ってるからどちらもやらないとだけど、そのどちらともまずはJSを学ぶことが必要となるので、要は大変です・・・
参考リンク
りあクト! TypeScriptで始めるつらくないReact開発 第3.1版【Ⅰ. 言語・環境編】 - くるみ割り書房 ft. React - BOOTH
サバイバルTSを読んでのまとめ(第1回)
来月からWebアプリケーションのエンジニアとして働き始める。
転職先の会社ではTypeScriptとReactを使うようなので、最近その2つの言語を教材をいくつか用いて勉強している。
TSの方は知り合いのエンジニアの方から「サバイバルTypeScript-TypeScript入門」をお勧めしてもらったので、現在それに取り組み始めたところである。
せっかくなので学んだことを軽くまとめたいと思い、こうして記事に残している。本書の章や節に沿って学んだことをざっくりまとめていこうと思う。
「TypeScriptはスケールするJavaScript」
TSはJSの上位互換としての言語であり、その違いを雑にざっくり述べると、ちゃんとスケールをするという点が挙げられる。
ではスケールとはなんぞや、というと、開発に携わる人数やコードの規模が多くなった場合でも正常に機能することを指すようだ。 こう書かれていると当然「JSだとスケールしないのか」という考えが浮かぶけれども、これはどうやら「しない(むずかしい)」という認識で正しいらしい。
こちらの記事にその理由が書かれていた。
JavaScript がある定常以上の規模となると、下記の理由から実装・保守の効率が非常に悪くなります。
- 型の定義がないので、意図しない値が入ることがある。
- null safety でないので、意図しない null や undefined が入ることがある。
- オブジェクト指向言語だが、インターフェースやクラス定義がなく、プロパティ名を間違っていても実行時までエラーにならず、エラーになっても原因の解析に時間がかかることが多い。
- 型やインターフェース、クラス定義がないので、エディタによる入力補完があまり受けられない。
上記はJSの弱みと言えるわけだけれど、TSは型を導入することでその弱みを補強し、かつJSと互換性を持った言語のため、上位互換の言語として広く受け入れられているようだ。
ほぼJSの弱みの裏返しだが、具体的には以下の点で補強がなされている。
- コンパイル時に型の制約を破っている箇所を教えてくれる
- TypeScript側で自動で型を推定・補完してくれる。そのため開発者側はあらゆる箇所に型を設ける必要はない
TypeScriptと関係のある技術
TSはその開発を助けるツールと一緒に使われることが多々ある。以下ではその具体的なツールを列挙する。
モジュールバンドラ
タスクランナー
- フロントエンド開発においてある決められた処理を自動化するツール。具体的には、ファイルの変更の監視やコンパイル、圧縮等のタスクを自動化している。gulpやgruntが有名
パッケージマネージャー
- 必要なJSライブラリのインストールとライブラリ間の依存関係を調整してくれるツール。npmやyarnが有名
Node.js
Node.jsはJSをサーバーサイドで実行できるようにするために開発されたソフトウェア。サーバー・端末側でJSを実行するための土台の役割を果たす。
JSでサーバーに関する処理を行えるようにするため、Node.jsは例えば以下のAPIを有している。
経緯としてはそうした形だが、最近ではフロントエンドの開発でも利用されている。なぜなら上述したWebpackなどの便利なツールの多くがNode.jsを用いて書かれているものであり、それらを利用するためにはNode.jsの導入が必須となるためである。
またJSを実行する土台となる実行環境は、ブラウザとnode.jsの2つがある。ブラウザやNode.jsの内部にはv8というJSを評価して実行するためのエンジンが組み込まれているらしい。
ただ同じエンジンが入っているものの、ブラウザとNode.jsでは所持しているAPIで微妙に異なるところがある。例えばブラウザにはDOM APIという、JSからDOMにアクセスをして、タグで挟まれた要素の内容を変更するためのAPIが実装されているが、Node.jsにはない。
一方でNode.jsにはFS(File System)という、文字通りファイルシステムにアクセスをして、ファイルの読み書きを行うためのAPIが実装されている。が、同様にブラウザではこれは実装されていない。
型があることでうれしい事例
JSで以下のようなコードがあったとして・・・
function increment(num) {
return num + 1;
}
console.log(increment('1'));
このコードを実行すると出力されるのは「11」だ。 本来1+1の演算結果を出力して欲しかったとして、それができていない理由は関数を呼び出している引数が、数値でなく文字列となっているためである。
このコードの拡張子をJSからTSに変換すると、エディタから以下のような推奨を受ける。
パラメーター 'num' の型は暗黙的に 'any' になっていますが、使い方からより良い型を推論できます。ts(7044)
そこで関数の引数の型を以下のように設定する。
function increment(num: number) {
return num + 1;
}
console.log(increment('1'));
すると設定した型と関数を呼び出した際の引数の型が異なるためエディタから以下のように怒られる。
型 'string' の引数を型 'number' のパラメーターに割り当てることはできません。
これをこのままコンパイルしようとしても同様のメッセージのエラーが表示されて実行できず、コードを正しく修正することが可能となる。
改めてにはなるが、なので型があるうれしさとしては、こうしたコード中にある問題や危険性をコーディング・コンパイルの時点で事前に気づくことが可能な点が挙げられる。
まとめていないまとめ
Node.jsってすごい。ただ「webpackはNode.jsで書かれています」みたいな記事が割と散見されるのだけれど、Nodeって実行環境であり言語という認識で大丈夫なのかな?